The Probabilistic Digital Twin Concept¶

Risk models usually start where digital twins often stop. While digital twins live alongside physical assets and are maintained throughout their life cycle, risk models are typically only used in the design phase, in connection with major modifications or events, or when regulators require risk assessments to be updated. Risk assessments typically involve multiple models from various domains, and many of these may be too computationally heavy to run in real time during operation, or may not have the necessary detailing level to capture the dynamics of risk at the required timescales relevant to operational decisions. So, while operational decisions would benefit from being risk-informed, the current risk models do not offer this value.
By connecting digital twins to risk models that capture uncertainties about the future, it is possible to provide up-to-date and on-line risk assessments that reflect actual conditions and operation scenarios.
Challenges of applying digital twins to risk analysis¶
Several challenges need to be overcome to make digital twins suitable for online risk assessment:
- While digital twins contain a lot of information, this information will never be complete, and it may also be imperfect. Such uncertainty is important, because deviations from what we expect can be more important than what we expect when it comes to safety. To be useful for on-line risk assessment, digital twins should capture uncertainties.
- Coupling risk models to digital twins means more than simply running risk models with parameters tuned to current conditions and replacing input distributions with new data from a digital twin. Rather, data in digital twins is a supplement to the vast domain knowledge and experience data contained in risk models. To be useful for on-line risk assessment, relevant prior knowledge from design risk models should be transferred to digital twins and updated as new information becomes available.
- Digital twins are typically used to test or manage the performance of a system under given conditions or in the presence of specific failure modes. However, they typically lack models for the variability of conditions or the processes leading to failures. Furthermore, risk entails uncertainty about sequences of events that could lead to losses (e.g. fatalities, injuries, pollution, damage or monetary costs). Many such losses are not attributes of an asset or its digital twin itself, but relate to its operating context and environment. To be useful for on-line risk assessment, digital twins need to be equipped with models of degradation and failure processes, and models for how performance and failures relate to losses, including how these are affected by environmental conditions, operating strategies and external influencing factors.
- Digital twins often aim to mirror physical assets in great detail and simulate their behaviour with high fidelity. Accordingly, the simulation models contained in digital twins are often computationally expensive to run. The need to propagate uncertainty through the models, account for variability in conditions, and test multiple operation strategies can increase computational demands by additional orders of magnitude. When it comes to safety, being able to simulate particular scenarios with high accuracy may be less important than being able to simulate a wide range of scenarios to explore the effects of uncertainty. Hence crude, but fast, models may be preferred over detailed, but slower, models. To be useful for on-line risk assessment, we need predictive models that are fast to query, so that it is feasible to couple them to other models and propagate uncertainties through them.
Building blocks of a probabilistic twin¶
As a solution to the above challenges, we propose probabilistic digital twins (PDTs). PDTs add a layer of probabilistic risk models to digital twins, to capture uncertainty and model the effect of knew knowledge and actual conditions on safety. Specifically, this may include (see Fig. 3):
- Failure and degradation models: These are important because many loss events considered in risk assessments relate to component failures. While failure and degradation can be related to physics, they cannot be described deterministically in the way we describe the operation of a system. Rather, degradation and failure are characterized by aleatoric uncertainty, which requires probabilistic/stochastic models.
- Logic and relational models: Models that can encode logic and uncertain relationships between performance variables, failures and loss events.
- Surrogate models: Approximations of heavier simulation models, or empirical models, that allow fast exploration of scenarios, propagation of uncertainty, and model coupling.
These elements are justified and described in more detail below. An example use case and implementation of a probabilistic digital twin containing these elements is described in the next section, together with a corresponding interactive user interface.
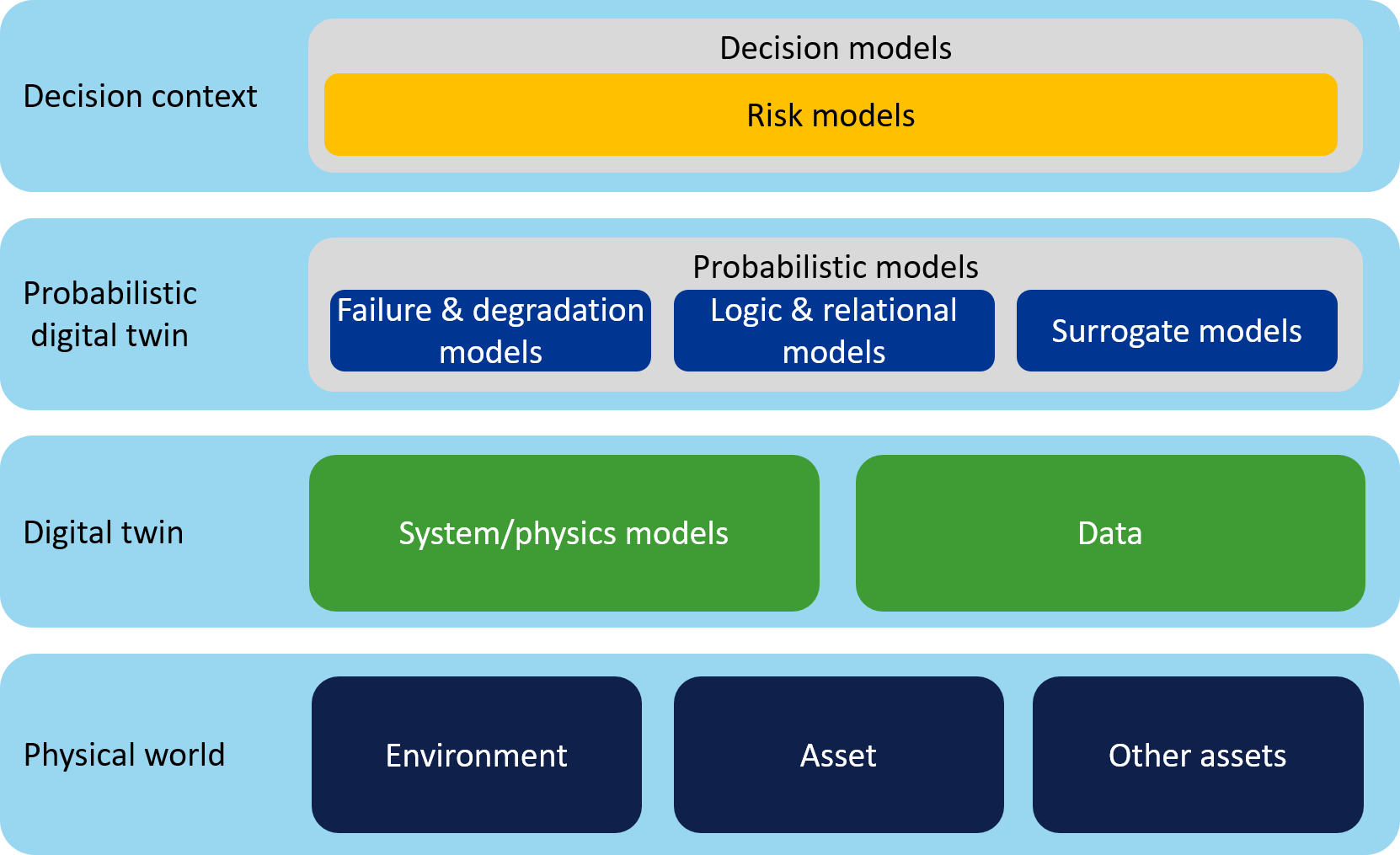
Fig. 3 A digital twin contains models and data collected from the real asset, other similar assets and the environment. A probabilistic digital twin additionally contains probabilistic models, including failure and degradation models, logic and relational models and surrogate models, which make it possible to use the information from a digital twin for risk assessment and decision support.
Failure & degradation models¶
Digital twins typically contain models of how systems work, which are mostly deterministic. However, in risk assessments we are concerned with system failures and degradation, which are associated with both variability (aleatory uncertainty) and incomplete or imperfect knowledge (epistemic uncertainty). Degradation and failure are typically modelled as random processes, or represented in terms of probability distributions for the time to failure or the probability that loads exceed capacity during a specified time interval.
Quantitative risk assessments (QRAs) are typically based on failure frequencies computed from generic historic failure data that are not specific for the asset under consideration. Structural reliability analyses (SRAs) compute failure probabilities based on the physics of an actual structure design, but they also rely on assumptions and probability assignments made before the systems go into operation. By including such probabilistic QRA and SRA models in a probabilistic digital twin, it is possible to continuously update failure probabilities and estimates of remaining life time based on information available in the digital twin, such as loading history, test results, and inspection and maintenance records. In fact, having a digital twin for an asset, it may be possible to replace QRA and SRA models that focus on failure events with more detailed models that capture the underlying physical degradation processes leading to failure (e.g. relating failure rates in QRA models to physical parameters, or explicitly model the processes affecting how the capacity and load distributions change over time in SRA models). Examples include corrosion and fatigue related failure modes, which depend on the system’s environment and operation.
Logic & relational models¶
Logic models and relational models can be used to relate variables and attributes from a digital twin to events and losses of concern with respect to safety. While the models used to model performance are typically based on equations or rules, risk models are typically based on models of causal relations and chains of events. For example, failure scenarios are often modelled with fault trees which encode the logic of which combinations of components that must work in order for a system to work. Similarly, event trees are often used to encode the logic of how accidents unfold (e.g. gas leak -> ignition -> explosion -> damage). In SRA, failures are modelled as events where a load exceeds a capacity, where the load and capacity probability distributions in turn are related to underlying quantities and events.
Probabilistic graphical models (PGMs) are more general approaches to model uncertain relationships between uncertain variables and events. Bayesian networks, constitute a class of PGMs that is often used in risk analysis, which relate the state of different variables via conditional probability distributions. Bayesian networks allow one to reason consistently about related variables by combining prior knowledge with new evidence, according to Bayes rule (described below).
Logic and relational models enable the coupling of models from different domains without explicitly simulating them together. Bayesian networks also enable Bayesian updating of probability distributions as new knowledge becomes available, and to query the effect of different actions. These features are essential for managing dynamic risk in operations.
Bayes’ rule
Bayes’ rule is an important pillar of Bayesian statistics and probability theory, providing a means of updating beliefs based on new evidence. It can be stated as
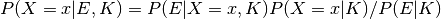 ,
,
where 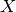 is something uncertain we want to express a belief about, e.g. some variable or relationship. In this formula,
is something uncertain we want to express a belief about, e.g. some variable or relationship. In this formula, 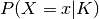 is the (prior) probability originally assigned to
is the (prior) probability originally assigned to 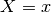 , expressing beliefs or confidence about being
, expressing beliefs or confidence about being 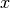 (i.e. ), based on prior knowledge
(i.e. ), based on prior knowledge 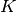 . Similarly,
. Similarly, 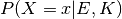 is the new (posterior) probability assigned to after also taking into account the new evidence
is the new (posterior) probability assigned to after also taking into account the new evidence 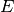 .
.
The factor 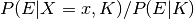 that link the prior and posterior probabilities represents the degree to which the new evidence supports our prior beliefs about . More specifically, the numerator
that link the prior and posterior probabilities represents the degree to which the new evidence supports our prior beliefs about . More specifically, the numerator 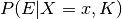 denotes the likelihood of obtaining the evidence if , and the denominator
denotes the likelihood of obtaining the evidence if , and the denominator 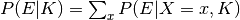 sums up the corresponding likelihoods of obtaining the same data for all possible values/states of . Thus, the change in belief will be larger the more surprising the evidence is with respect to prior knowledge.
sums up the corresponding likelihoods of obtaining the same data for all possible values/states of . Thus, the change in belief will be larger the more surprising the evidence is with respect to prior knowledge.
While a digital twin may be considered a digital representation of the physical attributes , knowledge and collected evidence about a system, a probabilistic digital twin is a digital representation of uncertainty, i.e. also containing the element .
Surrogate models¶
Surrogate models are efficient approximate models that can be used as substitutes for more computationally heavy simulation models or constructed from observation data.
In risk analysis, where we may need to explore vast numbers of scenarios, surrogate models are often constructed from a high-fidelity model, an then the surrogate models are used for fast approximation and uncertainty analysis. This is for example the case with computational fluid dynamics models for fires and explosions, or finite element models for simulation of structures’ responses to loads. Surrogate models can also be constructed based on empirical data from physical experiments and used to estimate outcomes for unobserved input combinations.
To couple the physics models in a digital twin to risk models, it may be necessary to create intermediate surrogate models that are faster to query, so that predictions can be provided in real time and uncertainty propagation becomes feasible.
Digital twins could also be equipped with surrogate models to represent their environment (e.g. the weather) to allow simulation of hypothetical scenarios. With the introduction of artificial intelligence, we see autonomous systems that learn from observation and experience, and construct their own surrogate models of their environment to anticipate events and optimize decisions (i.e. Reinforcement learning). However, one could also imagine equipment vendors offering surrogate models as an interface to their digital twins, allowing exchange of digital twins and co-simulation of large systems without revealing the inner workings of components or compromizing intellectual property rights.
Various statistics or machine learning methods can be used to construct surrogate models. However, for high risk applications models need to provide information about the uncertainty associated with predictions. For the demonstration described in the following sections, we have used Gaussian Process (GP) regression models, which include uncertainty in predictions. GPs also have the advantage of being non-parametric (i.e. not assuming a particular functional form), while at the same time allowing imposition of constraints, such as smoothness, symmetries, boundedness, monotonicity or convexity [1]. For more explanation and examples of GPs, see our position paper on AI + safety [2].